컴퓨터의 CPU는 연산을 해주고 램은 메모리에 해당한다.
램에 저장된 데이터를 연산을 하기 위해 CPU에서 꺼내서 사용하게 될 것이다.
그런데 접근해서 사용할 때 마다 먼거리를 이동하게 되면 쓸데없는 시간 낭비를 하게 된다.
CPU는 굉장히 빨라서 빠르게 동작하는데, CPU 혼자만 동작하는 경우는 잘 없고 어떠한 데이터를 꺼내서 연산을 하게 된다.
그리고 데이터를 꺼내서 전송하는 비용이 CPU 연산 비용에 비해서 훨씬 크다.
그래서 매번 데이터를 필요로 할 때마다 램에 접근해서 데이터를 꺼내쓰는 것은 올바른 방법이 아니다.
이를 해결하기 위해 '캐시'를 도입하였다.
캐시는 말 그대로 임시 저장소 같은 개념이다. (영구적으로 사용되고 그런 개념이 아니다.)

위의 사진 처럼 메모리의 계층 구조는 피라미드 형식으로 되어 있다.
캐시에는 딱 하나의 캐시만 있는게 아니라 단계별로 L1캐시, L2캐시, L3캐시 등이있다.

그리고 피라미드 구조의 위로 갈 수록 용량은 적지만 코어에 빠르게 접근 할 수 있다.
반대로 아래로 갈 수록 용량은 크지만 코어에 접근하는 비용이 늘어난다.
그럼 캐시가 어떻게 위의 문제점을 해결했는지 알아보자.
- 원하는 데이터가 있으면 우선 캐시를 전부 뒤지고, 캐시에 원하는 데이터가 없으면 그 때 램으로 이동하여 데이터를 꺼내오게 된다.
- 어떠한 데이터를 램에서 꺼내 올 때 혹시나 다음에 필요 할 수도있으니 우선 캐시에 저장하게 된다.
- 후에 동일한 데이터를 필요로 하게 되면, 캐시 메모리 중에서 해당 데이터 주소의 값을 들고있는지 체크하고 내가 알고있는 값이라면 램까지 가지 않고 캐시에 있는 데이터를 꺼내서 사용하게 된다.
- 하지만 캐시 메모리의 용량이 크지 않다 보니 사용 빈도가 적거나, 제일 오래된 녀석을 폐기하고 새로운 데이터로 덮어 씌운다.
근데 캐시는 굉장히 작은데 상대적으로 매우 큰 메인 메모리로부터 어떻게 가져와 저장할 수 있을까?
이건 Locality (지역성) 때문이다. 지역성에는 2가지 종류가 있다.
1. Temporal Locality (locality in time)
- cpu가 lw x5, 4(x0) 명령어를 동작한다 했을 때, 메인 메모리에서 목적지 x0를 얻는다. 근데 x0가 가까운 미래에 또 사용될 확률이 매우 높으니 이 데이터를 캐시에 저장한다. 이걸 시간 지역성이라고 한다.
2. Spatial Locality (locality in space)
- 한번 접근한 데이터로부터 주변의 데이터를 또 사용할 것이라고 생각해 그 주변을 데이터까지 캐시로 가져오는 것이다. 대표적으로 배열이 이에 해당된다.
예제 코드를 보자.
int32 buffer[10000][10000];
int main()
{
memset(buffer, 0, sizeof(buffer));
{
uint64 start = GetTickCount64();
int64 sum = 0;
for (int32 i = 0; i < 10000; i++)
for (int32 j = 0; j < 10000; j++)
sum += buffer[i][j];
uint64 end = GetTickCount64();
cout << " Elapsed Tick : " << (end - start) << endl;
}
{
uint64 start = GetTickCount64();
int64 sum = 0;
for (int32 i = 0; i < 10000; i++)
for (int32 j = 0; j < 10000; j++)
sum += buffer[j][i];
uint64 end = GetTickCount64();
cout << " Elapsed Tick : " << (end - start) << endl;
}
}첫 번째 for문과 두 번째 for문의 차이점은 buffer에 접근할 때 buffer[i][j]로 접근하냐 buffer[j][i]로 접근하냐의 차이이다.
그럼 둘다 똑같이 10000x10000 접근할 텐데 뭐가 다르겠나 싶지만 실행해보면 서로 다른 결과값이 나오게 된다.

첫 번째(buffer[i][j]) for문이 두 번째(buffer[j][i]) for문 보다 더 빠르게 실행되는 것을 알 수 있다.
왜냐하면
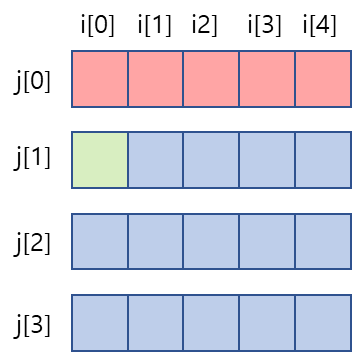
아래 예시 그림 처럼 2차원 배열(buffer)의 메모리가 있다고 할 때,
첫 번째 for문으로 buffer를 순회하게 되면, j가 먼저 바뀐 다음에 j가 끝나면 i가 1늘어나는 상황으로 동작한다.
j가 하나씩 증가한다는 건 아래 그림 처럼 이동하면서 데이터를 쓴다.

우리가 buffer[0][0]의 데이터가 필요해서 램에서 가져온다고 할 때, buffer[0][0]에 해당하는 데이터만 가져오는게 아니다.
위에서 말한 Spatial Locality 특징 때문에 블럭단위로 인접한 데이터를 가져와서 캐시에 저장해 주게 된다.

이 상태에서 다음 데이터인 buffer[0][1]을 찾으려고 캐시에 해당 데이터가 있는지 찾아보면,
운좋게 바로 이전 데이터 옆에 있던 데이터라 캐시에 저장되어 있기 때문에 램 까지 가지 않고 캐시 메모리에서 데이터를 가져 올 수 있게 된다. 그리고 이러한 상황을 '캐시 히트'라고 한다.
그래서 첫 번째(buffer[i][j]) 경우는 캐시 히트가 연속해서 일어나기 때문에 빠르게 동작하게 된다.
반대로 두 번째(buffer[j][i]) 같은 경우에도 buffer[0][0] 데이터에 접근한다고 했을 때 ,

첫 번째 경우와 동일하게 Spatial Locality 때문에 buffer[0][0]의 데이터만 가져오는게 아닌 블럭단위로 인접한 데이터도 같이 가져오게 된다.

하지만 두 번째(buffer[j][i])는 바로 옆에 데이터를 가져오는게 아닌 j를 늘려서 다음 블럭으로 넘어가버리게 된다.
그래서 기껏 캐시 메모리에 인접한 데이터를 저장했음에도 저장한 데이터를 사용하지 않기 때문에 더 느리게 동작하게 된다.